

Diving into Software testing with large language model
Let’s dive deep into Software testing with large language model. Pre-prepared huge language models (LLMs) have as of late arisen as a leading edge innovation in normal language handling and man-made consciousness, with the capacity to deal with enormous scope datasets and show striking execution across a large number of errands. In the interim, programming testing is a significant endeavor that fills in as a foundation for guaranteeing the quality and dependability of programming items.
As the degree and intricacy of programming frameworks keep on developing, the requirement for more successful programming testing strategies turns out to be progressively critical, and making it a region ready for inventive methodologies like the utilization of LLMs. This paper gives an extensive survey of the use of LLMs in programming testing. It breaks down 52 important investigations that have involved LLMs for programming testing, from both the product testing and LLMs points of view.
The paper presents a nitty gritty conversation of the product testing errands for which LLMs are usually utilized, among which experiment readiness and program fix are the most delegate ones. It additionally dissects the usually utilized LLMs, the sorts of brief designing that are utilized, as well as the went with methods with these LLMs. It additionally sums up the vital difficulties and possible open doors toward this path. This work can act as a guide for future examination around here, featuring possible roads for investigation, and distinguishing holes in our ongoing comprehension of the utilization of LLMs in programming testing.
Introduction to software testing with large language model
Software testing is a crucial undertaking that serves as a cornerstone for ensuring the quality and reliability of software products. Without the rigorous process of software testing, software enterprises would be reluctant to release their products into the market, knowing the potential consequences of delivering flawed software to end-users.
By conducting thorough and meticulous testing procedures, software enterprises can minimize the occurrence of critical software failures, usability issues, or security breaches that could potentially lead to financial losses or jeopardize user trust. Additionally, software testing helps to reduce maintenance costs by identifying and resolving issues early in the development lifecycle, preventing more significant complications down the line.
The significance of Software testing with large language model has garnered substantial attention within the research and industrial communities. In the field of software engineering, it stands as an immensely popular and vibrant research area. One can observe the undeniable prominence of software testing by simply examining the landscape of conferences and symposiums focused on software engineering. Amongst these events, topics related to software testing consistently dominate the submission numbers and are frequently selected for publication.
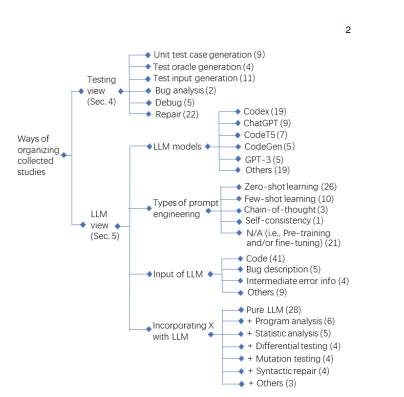
Recent large language models (LLMs), like T5 and GPT-3, have revolutionized natural language processing (NLP) and artificial intelligence (AI). Specifically, advanced LLMs such as ChatGPT1 and LLaMA2 with billions of parameters show promise in code generation and artistic creation. However, concerns exist about the accuracy of the code they generate.
This article reviews the use of LLMs in software testing, analyzing 52 relevant papers. LLMs find a natural fit in tasks like test case preparation and program debugging. Challenges include accurate code generation and steering LLM behavior. The work aims to guide both researchers and practitioners in software engineering, providing insights into the current state and future potential of LLMs in software testing.
Background of large language model
Large Language Model (LLM) As of late, pre-prepared language models (PLMs) have been proposed by pretraining Transformer-based models over enormous scope corpora, showing solid abilities in settling different regular language handling (NLP) errands [12]-[15]. Studies have demonstrated the way that model scaling can prompt superior model limit, inciting analysts to examine the scaling impact through additional boundary size increments.
Software testing with large language model , when the boundary scale surpasses a specific limit, these bigger language models show huge execution upgrades, yet additionally extraordinary capacities, for example, in-setting realizing, which are missing in more modest models like BERT. To segregate the language models in various boundary scales, the examination local area has begat the term enormous language models (LLM) for the PLMs of huge size. LLMs normally allude to language models that have many (at least billions) of boundaries, and are prepared on enormous text information like GPT-3, PaLM, Codex, and LLaMA. LLMs are fabricated utilizing the Transformer design, which stacks multi-head consideration layers in an extremely profound brain organization.
Existing LLMs embrace comparative model structures (Transformer) and pre-preparing goals (language displaying) as little language models, however to a great extent increase the model size, pre-preparing information, and all out process power. This empowers LLMs to all the more likely figure out normal language and produce great text in view of given setting or prompts. Note that, in existing writing, there is no proper agreement on the base boundary scale for LLMs, since the model limit is additionally connected with information size and all out process.
In a new overview of LLMs [13], the creators centers around examining the language models with a model size bigger than 10B. Under their rules, the primary LLM is T5 delivered by Google in 2019, trailed by GPT-3 delivered by OpenAI in 2020, and there are in excess of thirty LLMs delivered somewhere in the range of 2021 and 2023 showing its prominence. In one more overview of bringing together LLMs and information charts [16], the creators sort the LLMs into three kinds: encoder-just (e.g., BERT), encoder-decoder (e.g., T5), and decoder-just organization engineering (e.g., GPT-3). In our audit, we consider the classification standards of the two studies and just consider the encoder-decoder and decoder-just organization design of pre-preparing language models, since the two of them can uphold generative errands.
We don’t consider the encoder-just organization design since they can’t deal with generative assignments, were proposed somewhat early (e.g., BERT in 2018), and there is practically no models utilizing this engineering after 2021. At the end of the day, the LLMs examined in this paper not just incorporate models with boundaries of over 10B (as referenced in [13]), yet in addition incorporate different models that utilization the encoder-decoder and decoder-just organization engineering (as referenced in [16], for example, BART with 140M boundaries and GPT-2 with boundary sizes going from 117M to 1.5B. This is likewise to possibly incorporate more examinations to exhibit the scene of this point.
Programming Testing Programming testing is a vital cycle in programming improvement that includes assessing the nature of a product item. The essential objective of programming testing is to recognize imperfections or mistakes in the product framework that might actually prompt erroneous or unforeseen way of behaving. The entire life pattern of programming testing commonly incorporates the accompanying assignments (exhibited in Figure 4):
● Necessities Examination: break down the product prerequisites and recognize the testing goals, extension, and rules.
● Test Plan: foster a test plan that frames the testing technique, test goals, and timetable.
● Test Plan and Audit: create and survey the experiments and test suites that line up with the test plan and the necessities of the product application.
● Experiment Planning: the real experiments are arranged in view of the plans made in past stage.
● Test Execution: execute the tests that were planned in the past stage. The product framework is executed with the experiments and the outcomes are recorded.
● Test Revealing: examine the consequences of the tests and produce reports that sum up the testing system and recognize any deformities or issues that were found.
● Bug Fixing and Relapse Testing: deformities or issues recognized during testing are accounted for to the improvement group for fixing. When the imperfections are fixed, relapse testing is performed to guarantee that the progressions have not presented new deformities or issues.
● Programming Delivery: when the product framework has passed all of the testing stages and the deformities have been fixed, the product can be delivered to the client or end client. The testing system is iterative and may include different patterns of the above stages, contingent upon the intricacy of the product framework and the testing necessities. During the testing stage, different sorts of tests might be performed, including unit tests, joining tests, framework tests, and acknowledgment tests.
● Unit Testing includes testing individual units or parts of the product application to guarantee that they capability accurately.
● Joining Testing includes testing various modules or parts of the product application together to guarantee that they work accurately as a framework.
● Framework Testing includes testing the whole programming framework in general, including every one of the coordinated parts and outside conditions.
● Acknowledgment Testing includes testing the product application to guarantee that it meets the business prerequisites and is prepared for arrangement.
FAQs:
- What is the significance of software testing in the development lifecycle?
- Software testing ensures the quality and reliability of software products, preventing critical failures and security breaches.
- How do large language models (LLMs) like T5 and GPT-3 impact software testing?
- LLMs offer innovative approaches to software testing, aiding tasks such as experiment preparation and program debugging.
- Which testing tasks commonly involve the use of LLMs?
- LLMs are frequently used for tasks like test case preparation and program repair, addressing specific challenges in software testing.
- What are the potential challenges and opportunities in utilizing LLMs for software testing?
- Challenges include accurate code generation, while opportunities lie in extending LLM applications to diverse testing types and providing comprehensive benchmark datasets.
- How do LLMs fit into the iterative software testing process?
- LLMs find a natural fit in different testing stages, contributing to tasks like test execution and bug fixing in the iterative testing process.
Conclusion:
- The integration of large language models (LLMs) in software testing presents innovative solutions to challenges.
- LLMs excel in tasks like experiment preparation and program debugging.
- Challenges include ensuring accurate code generation, while opportunities lie in expanding LLM applications and enhancing benchmark datasets.
- This work serves as a guide for future research, highlighting potential avenues for exploration and identifying gaps in understanding LLMs in software testing.
You may be interested in:
Effective Test Case Design: A Comprehensive Guide
What is Spiral Models in Software Testing?